OK, so it's not really "new." It's a little over a year old, but the Drupal community on Gittip just recently got over 150 people which is the threshold where Gittip starts displaying members of the community.
So, congratulations to the Drupal Community! (and to Gittip).
Why is Gittip a useful tool for the Drupal community?
I think a lot of people want to give a little support (via money) to the people who work on Drupal but there is a lot of friction in the way of giving money. Does the person use Paypal? What is their PayPal email? What if you only want to give someone $10? The friction of that whole transaction far outweighs the $10 gift.
There's also a mismatch in the action: most payment systems like a check or PayPal are used one-time (again, because of the friction) but the benefit from a contribution and the desire to pay back that benefit live on for as long as you have a Drupal site. A lot of these topics are discussed in an old Lullabot Podcast where they point out that if every active user of Views gave Earl a few dollars for their use of he'd have a bit over $2 million.
My perspective is that it hasn't been easy enough for people to give that money and the friction is holding them back. Gittip solves a lot of these friction problems and the timing problem by making it easy to do small recurring payments to anyone on github or twitter.
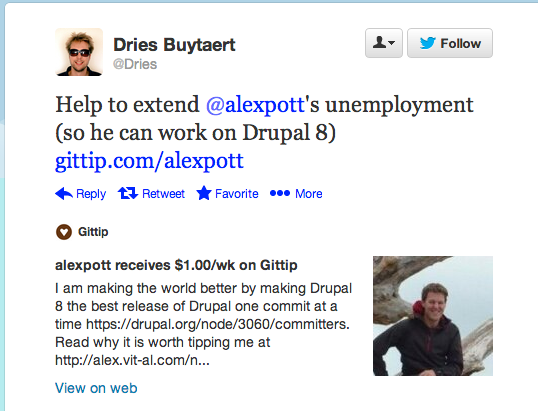
One example that Dries requested: let's help AlexPott extend his "unemployment" and let him focus his genius on Drupal 8 core development!
What does the evolution of our use of Gittip look like?
Among the people who have joined the Drupal community on Gittip: